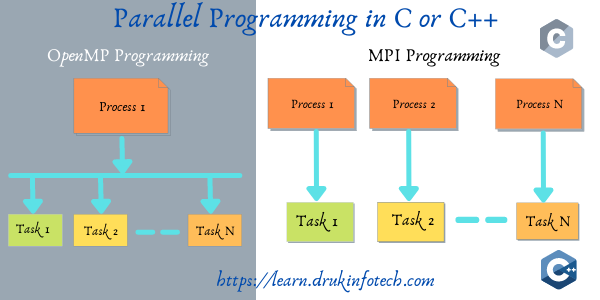
MPI stands for Message Passing Interface. It is used to make communication between different processes in the same machine or across different machines in a network in a distributed environment. So that the task can be parallelized and work can be done faster. The MPI has made the parallelizing tasks very easy. It is available in the form of a standard library. The parallelism between different processes can be achieved with help of a rank.
The MPI library assigns the different processes with a unique number called a rank. The rank starts from 0 to n-1. If there are 4 processes then each process will be assigned a unique rank ranging from 0,1,2, and 3. These ranks can be used to differentiate and communicate between the different processes. You can read more about the MPI programming at MPI Tutorials. In this post, we will see how we can compute the array sum using MPI programming.
MPI Programming
In order to start programming using MPI, you need to install the library first and then you can import the library and use it.
Installing MPI Library
You can download the MPI binary from the MPI Downloads. It is available for Linux Distro, Windows OS, and Mac OS. Then follow the instruction accordingly to install it on your machine. You can directly install it in Ubuntu. Just type “mpicc” in the terminal. It will give the command to install it. Copy the command and run it in the terminal.
You can include the mpi library in you C/C++ program by “#include<mpi.h>”.
A Simple MPI Program Structure
A simple MPI program written in C is given below to understand the MPI. The first process will print the “How are you?” message and the rest will print out ” I am Fine”.
#include<stdio.h>
#include<mpi.h>
int main(int argc, char *argv[]){
int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0){
printf("Rank %d: How are you?\n", rank);
}else{
printf("Rank %d: I am Fine\n", rank);
}
MPI_Finalize();
return 0;
}Some of the MPI library functions and variables that you can notice from the above code are as follows:
- MPI_Init() – It initialize the MPI
- MPI_Comm_size() – It determines the total number of processes in a group.
- MPI_Comm_rank() – It determines the id of the calling process.
- MPI_Finalize() – It binds the MPI program.
- MPI_COMM_WORLD – It is a communicator between processes.
How to Compile and Run MPI Program?
In order to compile the program, you need to run the “mpicc” command.
# mpicc -o objectname programname.cFor example, if the program name is “hello_mpi.c”, then you can compile it as “mpicc -o hello_mpi hello_mpi.c”.
Now you can run the program with “mpirun” command. You can run literally on any number of processes.
# mpirun -np total_process_number ./objectnameFor example, you can run “hello_mpi.c” as “mpirun -np 4 ./hello_mpi” once the program code is successfully compiled.
Functions Available in MPI Library
Some of the frequently used functions of MPI are as follows:
- MPI_Send()
- MPI_Recv()
- MPI_Scatter()
- MPI_Gather()
- MPI_Reduce()
- MPI_Bcast()
- MPI_Barrier()
The documentation of every function can be found at MPI Functions Documentation.
Array Sum Using MPI Programming
Array sum is the summation of the array elements. In order to find the sum of the array, divide the array into equal chunks array(sub-array) and assign it to each process(load balancing). The number of sub-array depends on the number of processes because each process will get an equal size of the sub-array. The block distribution load balancing technique is used. As each process will get the consecutive block of array elements.
Then each process will compute the local sum of the sub-array and send it to the master process to compute the global sum of the array which will be the sum of the original array. Then will display the sum of the array from the master process.
Pseudocode of Array Sum Using MPI
Input: The number of processes.
Output: The sum of all sub-array and the final sum of the array.
//n is the size of the array
//p is the total number of process
//rank 0 is called master process and other ranks are called worker processes
Algorithm arraySum(){
if rank is 0 then
//Initialize the array with size n
arr[n] ={}
array_element_per_process = n/p
for i=1 to p-1 do
copy sub_arr[array_element_per_process] from arr[n]
send sub_arr[array_element_per_process] to rank i
send array_element_per_process to rank i
//Compute its own local sum
for i=0 to array_element_per_process do
local_sum +=arr[i]
print rank, local_sum
global_sum += local_sum
//Collect the local sum from rest of the processes
for i=1 to p do
receive local_sum from rank i
global_sum += local_sum
//Display the sum of the array
print global_sum
else then
receive sub_arr[array_element_per_process] from rank 0
receive array_element_per_process from rank 0
//Compute the local sum of array
for i=0 to array_element_per_process do
local_sum += sub_arr[i]
//Display the rank and local sum
print rank, local_sum
//Send the local sum to the master process
send local_sum to rank 0
}The above algorithm only gives the high-level flow of the program. It does not show what happens when the array size is not perfectly divisible by the number of the processes. But it is implemented in the source code below.
Source Code for Array Sum Using MPI
#include<stdio.h>
#include<mpi.h>
#define arr_size 15
int main(int argc, char *argv[]){
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
//Code that will execute inside process 0 or rank 0
if(rank == 0){
int arr[]= {12,4,6,3,21,15,3,5,7,8,9,1,5,3,5};
int global_sum = 0, local_sum = 0, recv_local_sum;
//If the array size is perfectly divisible by number of process.
if(arr_size%size == 0){
int array_element_per_process = arr_size/size;
int sub_arr[array_element_per_process];
for(int i=1; i<size; i++){
//Copying the sub array
for(int j=0; j<array_element_per_process;j++){
sub_arr[j] = arr[i*array_element_per_process+j];
}
//Sending array chunk of equal size to all the process.
MPI_Send(sub_arr, array_element_per_process, MPI_INT, i, 1, MPI_COMM_WORLD);
MPI_Send(&array_element_per_process, 1, MPI_INT, i, 1, MPI_COMM_WORLD);
}
//Calculating the local sum of rank 0 itself
for(int j=0; j<array_element_per_process; j++){
local_sum += arr[j];
}
printf("Rank %d: local sum: %d\n", rank, local_sum);
global_sum += local_sum;
//When the array size is not perfectly divisible by number of process.
}else{
int array_element_per_process = arr_size/size + 1;
int sub_arr[array_element_per_process];
for(int i=1; i<size; i++){
if(i == size - 1){
//last sub array will have the size less than other process array size
int total_array_size_of_last_process = arr_size - array_element_per_process * i;
for(int j=0; j< total_array_size_of_last_process; j++){
sub_arr[j] = arr[i*array_element_per_process+j];
}
MPI_Send(&sub_arr, total_array_size_of_last_process, MPI_INT, i, 1, MPI_COMM_WORLD);
MPI_Send(&total_array_size_of_last_process, 1, MPI_INT, i, 1, MPI_COMM_WORLD);
}else{
//Copying the sub array
for(int j=0; j<array_element_per_process;j++){
sub_arr[j] = arr[i*array_element_per_process+j];
}
MPI_Send(&sub_arr, array_element_per_process, MPI_INT, i, 1, MPI_COMM_WORLD);
MPI_Send(&array_element_per_process, 1, MPI_INT, i, 1, MPI_COMM_WORLD);
}
}
//Calculating the local sum of rank 0 itself
for(int j=0; j<array_element_per_process; j++){
local_sum += arr[j];
}
printf("Rank %d: local sum: %d\n", rank, local_sum);
global_sum += local_sum;
}
//calculating the global sum of the array
//Receving the local sum from the other process and updating the global sum
for(int i=1; i<size; i++){
MPI_Recv(&recv_local_sum, 1, MPI_INT, i, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
global_sum += recv_local_sum;
}
//Printing the output
printf("The sum of the array is %d\n", global_sum);
//Code that will get executed inside other than process 0 or rank 0.
}else{
//The other process will receive the chunck of array
int array_element_per_process = arr_size/size + 1;
int recv_sub_arr[array_element_per_process];
int recv_array_element_per_process, local_sum = 0;
MPI_Recv(recv_sub_arr, recv_array_element_per_process, MPI_INT, 0, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(&recv_array_element_per_process, 1, MPI_INT, 0, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
//Calculating local sum for the sub array
for(int j=0; j<recv_array_element_per_process; j++){
local_sum += recv_sub_arr[j];
}
//Printing the local sum
printf("Rank %d: local sum: %d\n", rank, local_sum);
//Sending back the local sum to the rank 0 or process 0.
MPI_Send(&local_sum, 1, MPI_INT, 0, 1, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}Note: If you want to check the program with different array sizes, then do change the value of the variable arr_size and arr respectively. You can not launch the process more than the number of array sizes. The program might crash or misbehave. But you can handle such scenarios as well if you want.
Conclusion
You have learned how to parallelize a C program using the MPI library. You basically parallelize the code using the concept of rank and communicator(communication channel). Each process is associated with the rank and assignment of rank to process is handled by the library internally. By parallelizing the task across the processes, you can complete the task faster.

I am an enthusiastic tech guy. Ever ready to learn new technology. I love building software solutions that can help mankind to solve problems.
You can support us by:
Becoming a patron at https://www.patreon.com/drukinfotech
Buy me coffee at https://www.buymeacoffee.com/drukinfotech